计算机组成原理

计算机组成原理
Hokori数据的表示
不同进制的转换
- 其他进制转十进制,使用按权展开法
- 十进制转其他进制,使用短除法
- 其他进制转其他进制
- 二进制转八进制,每三位划分开,然后将每三位都转成八进制
(二进制转十进制)
(二进制转八进制)
- 二进制转八进制,每三位划分开,然后将每三位都转成八进制
+ 二进制转十六进制,每四位划分开,然后将每四位都转成十六进制
(二进制转十六进制)
计算机结构
CPU
运算器
- 算数逻辑单元ALU
- 累加寄存器AC**(通用寄存器)**
- 数据缓冲寄存器DR
- 状态条件寄存器PSW**(用来存储运算过程中相关标记位)**
控制器
- 程序计数器PC**(了解下一条程序指令的位置)**
- 指令寄存器IR
- 指令译码器
- 时序部件
存储器
存储器的层次结构
\text{访问速度_{由快到慢}}\left\{ \begin{aligned} &\text{CPU内部(通用寄存器)}\\ &\text{Cache(按内容存取)(一般以K、M为单位,如256M)}\\ &\text{主存储器 (一般以G为单位,如512G)}\\ &\text{联机磁盘存储器} \\ &\text{脱机光盘、磁盘存储器} \\ \end{aligned} \right.
存储器分类
相联存储器
高速缓存(Cache)
使用Cache改善系统性能的依据是程序的局部性原理.
局部性原理
1 | int i,s=0; |
时间局部性原理
被引用一次的存储器位置未来也会被引用
空间局部性原理
如果一个存储器的位置被调用,那么将来他附近的位置也会被调用.
工作集理论
工作集是进程运行时被频繁访问的页面集合
虚拟存储
外存储器
-
磁盘存储器
-
光盘存储器
磁盘工作原理
磁盘结构于参数
存取时间=寻道时间+等待时间(平均定位时间+转动延迟)
寻找数据时候是先寻找磁道,再寻找扇区的
注意:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间.
由上可知存取时间=寻道时间+等待时间,由于寻道时间基本固定,因此需要的是等待时间最优化,故需要数据进行最优放置来优化等待时间,尽量达到无等待时间.
主存
分类
随机存取存储器
- DRAM
- SRAM
只读存储器
- MROM
- PROM
- EPROM
- 闪速存储器
编址
位的存储器
位的存储器
例:内存地址从AC000H到C7FFFH,共有(1)K个地址单元,如果该内存地址按字(16bit)编制,由28片存储器芯片构成.已知构成此内存的芯片每篇有16k个存储单元,则该芯片每个存储的单元存储(2)位.
(1) A.96 B.112 C.132 D.156
(2) A.4 B.8 C.16 D.24
解:
由此可见,这两个地址之间有112K个地址.
如上可知,一个地址单元有16bit,而总共的数据由28个存储器芯片构成.
而一个芯片有16K个存储单元,则可列等式:
这里涉及到两个东西,地址单元和存储单元不是一个东西,因此不能搞混了
bit=bit,存储的bit=内存数据bit
输入设备
输出设备
总线
内部总线
微机内部各个外围的芯片与处理器之间的总线.
系统总线
微机中各个插件板与系统的总线.
数据总线
用来传输数据的总线.计算机是32位代表一个计算机的字是32个比特位,说明总线的宽度是32个bit,一次传输的数据量是32个bit.
地址总线
地址总线是32位说明它代表的地址空间是2的32次方,即4G的宽度.因此32位的操作系统能够管理的内存只有4G.
控制总线
外部总线
微机与外部设备的总线.
计算机体系结构分类
从宏观角度
按处理机数量进行划分
单处理系统
并行处理与多处理系统
分布式处理系统
从微观角度
--------按并行程度进行划分--------
Flynn分类法
按指令流和数据流进行分类
| 体系结构类型 | 结构 | 关键特性 | 代表 |
|---|---|---|---|
| 单指令流单数据流 SISD |
控制部分:一个 处理器:一个 主存模块:一个 |
单处理系统 | |
| 单指令流多数据流 SIMD |
控制部分:一个 处理器:多个 主存模块:多个 |
各处理器以异步的形式执行同一条指令 | 并行处理机 阵列处理机 超级向量处理机 |
| 多指令流单数据流 MISD |
控制部分:多个 处理器:一个 主存模块:多个 |
被证明不可能,至少证明是不实际的 | 目前没有,有文献 称流水线计算机为此类 |
| 多指令流多数据流 MIMD |
控制部分:多个 处理器:多个 主存模块:多个 |
能够实现作业、任务、指令等全面并行 | 多处理机系统 多计算机 |
马译云分类法
按字/位并行度进行分类
- 字串行/字并行
- 位串行/位并行
Handler分类法
按硬件并行程度和计算机并行程度分类
Kuck分类法
按指令流和执行流进行分类
指令系统
指令集体系结构的分类
- 操作数在CPU中的存储方式
即操作数从主存中取出后保存在什么地方 - 显示操作数的数量
即在典型的指令中有多少个显示命名的操作数. - 操作数的位置
即任一个ALU指令的操作数是否能放在主存中,以及如何定位. - 指令的操作
即在指令集中提供哪些操作. - 操作数的类型与大小
CISC(复杂指令集计算机)
弊端:
- 指令集过于庞杂
- 处理速度降低
微程序技术是CISC的重要蜘蛛,每条复杂指令要通过执行一段解释性微程序才能完成,因此需要多个CPU周期,降低了处理速度. - 编译程序冗长、复杂
由于指令系统过于庞大,使高级语言编译程序选择目标指令的范围过大,并使编译程序本身冗长、复杂,从而难以优化哈编译使之生成真正高效的目标代码. - 动作繁杂、设计复杂、研制周期长
CISC强调完善的中断控制,势必导致动作反动、设计复杂、研制周期长 - 出错几率增大
CISC给芯片设计带来很多困难,使芯片种类增多,出错几率增大,成本提高而成本率降低.
CISC是早期的设计方案,为的是为不同的用户进行定制,因此可以实现不同的用户不同的指令.
RISC(精简指令集计算机)
关键技术:
- 重叠寄存器窗口技术
- 优化编译技术
- 超流水及超标量技术
- 在微程序技术中结合硬布线逻辑与微程序
流水线技术
流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术.
指令的执行顺序:取指令->分析指令->执行指令->
指令控制方式
- 顺序方式
- 重叠方式: 通常一次重叠
- 流水方式
流水线计算
- 未使用流水线
| 取指令 | 1 | 2 | 3 | 4 | ||||||||
| 分析指令 | 1 | 2 | 3 | 4 | ||||||||
| 执行指令 | 1 | 2 | 3 | 4 |
- 使用流水线执行指令
| 取指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 分析指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 执行指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
-
流水线周期为执行周期最长的一个执行阶段
-
流水线计算公式为:1条指令执行时间+(指令条数-1)*流水线周期
-
理论公式:
代表的是执行指令经历的阶段数量,代表每一个阶段所花费的时间,n代表执行指令的条数 -
实际公式:
其中为流水线周期,也就是执行周期里最长的一个阶段
-
考试时首先用到理论公式,理论公式没有正确值时(该题目一般在选择题出现,若在计算题,则两个公式都计算一次),再按实践公式计算
例:若指令流水线把一条指令分为取指、分析和执行三部分,且三部分的时间分别是取值2ns,分析2ns,执行1ns.那么流水线周期是多少?100条指令全部执行完毕需要的时间是多少?
理论时间:
实际时间:
若是不使用流水线,所需要花费的时间:
流水线吞吐率计算
吞吐率是指在单位时间内流水线所完成的任务数量或输出的结果数量
公式如下:
如上例子所示的吞吐率为:
流水线最大吞吐率计算
如上例子所示的最大吞吐率为:
流水线加速比
\begin{align} S=\frac{不使用流水线的执行时间}{使用流水线的执行时间} \end{align}
如上例子的流水线加速比为:
流水线效率
指流水线的设备利用率.在时空图上,流水线的效率定义为N个任务占用的时空区与k个流水段总的时空区之比
公式如下:
\begin{align} E=\frac{N个任务占用的时空区}{K个流水段的总时空区}=\frac{T_0}{kT_k} \end{align}
流水线的效率计算,通俗的来说就是用标记了的方块面积除以整个长方形的面积
如上例子的流水线效率为:
可以得出流水线效率为0.8倍.
可靠性
串联系统的可靠度计算
R为总的串联系统可靠度,为每个系统可靠度,为总的失效率,而\lambda_x为每个系统的失效率,即单位时间内失效的元件数与元件总数的比例
计算失效率的公式是简化的近似公式,只有当子系统较多,且失效率极低的时候可以用这种方式计算.
并联系统的可靠度计算
其中为总的失效率
模冗余系统
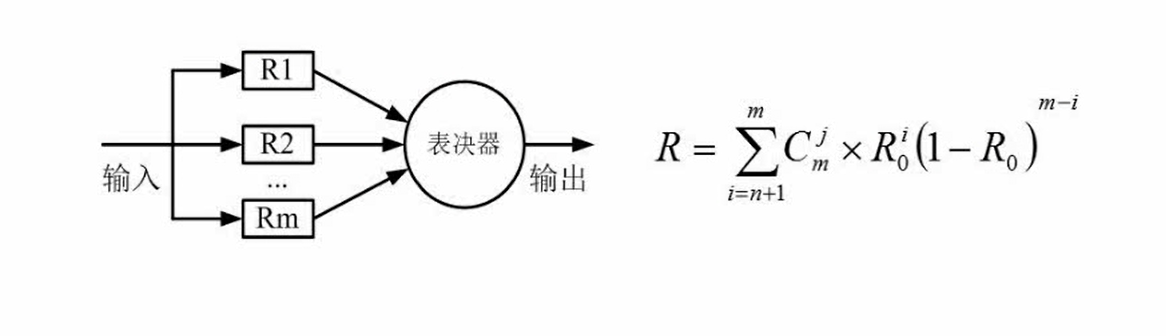
多个子系统独立,每个系统都进行计算,系统最终采纳的结果通过表决决定,利用少数服从多数的原理,把一些错误屏蔽掉.
m为子系统的个数,i为相应的值
混合系统
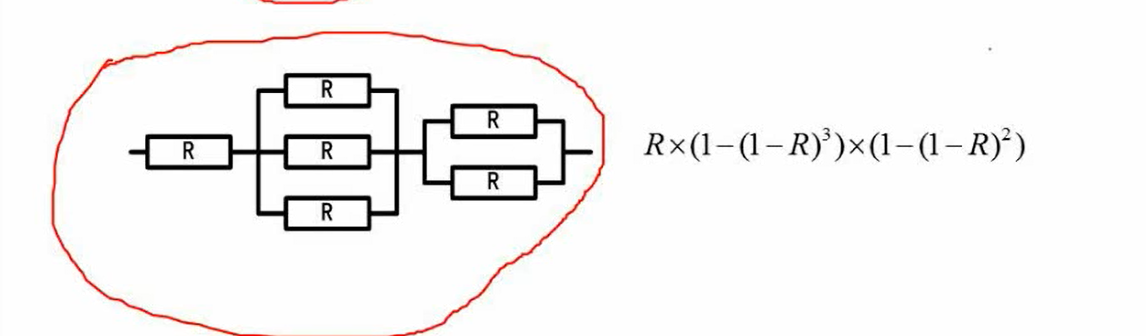
混合系统先从整体看时串联还是并联
差错控制
码距
一个编程系统的码距是整个编码系统种任意(所有)两个码字的最小距离.
例:
若用1位长度的二进制编码.若A=1,B=0.这样A,B之间的最小码距为1.
若用2位长度的二进制编码,若以A=11,B=00为例,A、B之间的最小码距为2.
码距与检错、纠错有何关系?
1、在一个码组内为了检测e个误码,要求最小码距d应该满足,d>=e+1
2、在一个码组内为了纠正t个误码,要求最小码距d应该满足,d>=2t+1
奇偶校验码
这种方式通过在编码中增加一位校验位来使编码中1的个数为奇数(奇校验)或者为偶数(偶校验),从而使码距变为2.
| 校验位 | 数据位 |
|---|---|
| 1 | 11100000 |
| 1 | 11000000 |
数据位有3位,为奇数,则校验位为1
缺点:
1、只能检测出奇数位错误,无法检测出偶数位错误
2、只能检测出错误,无法检测出错误的地方
水平奇偶校验码
对每一个数据的编码添加校验位,使信息位与校验位处于同一行
垂直奇偶校验码
把数据分成若干组,一组数据排成一行,再加一行校验码. 针对每一行列采用奇校验 或 偶校验
水平垂直校验码
CRC
它利用多项式为k个数据位产生r个校验位来进行编码,其编码长度为k+r.CRC的代码格式为:
其中,n为整个CRC码的字长,则k+r=n,而这个码又称为(n,k)码
| 校验位 | 数据位 |
|---|---|
| 0~r | 0~k |
| n n-1 …r+1 | r r-1 … 1 |
| CRC的校验步骤有: | |
| 循环冗余校验同其他差错检测方式一样,通过在要传输的k比特数据D后添加(n-k)比特冗余位(又称帧检验序列,Frame Check Sequence,FCS)F形成n比特的传输帧T,再将其发送出去. | |
| 1、先选择一个多项式,用于在接收端进行校验时对数据帧进行校验. | |
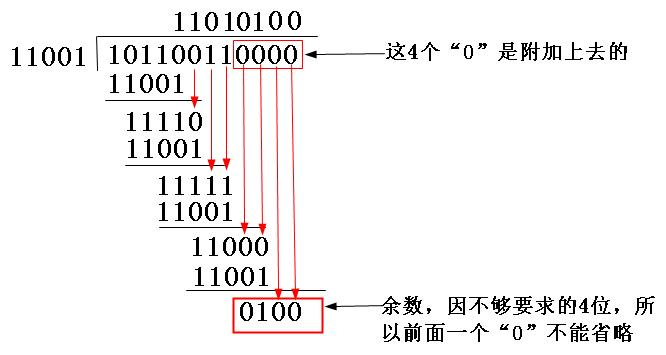
| 2、在要发送的数据帧后面加k-1个0,(k为选定的多项式位数),并用加完之后的数据帧以“模二除法”方式除以多项式,余数便是该帧的CRC校验码. | |
| 3、把校验码加在原数据位上,即生成了最后的数据帧,把这个新的帧发到了接收端,接收端对这个新帧以“模二除法”除以之前选择的除数,如果没有余数,则表明该帧在传输过程中没有出错,否则便出了差错. | |
| T mod P == 0 ……(1) | |
| 其中 |
生成多项式的方法.
一般来说,多项式题目都会给…
数据位为:10011,则多项式
模二除法
二进制中的逻辑异或计算,即比较后,两者对应位相同则结果为0,否则为1.
CRC可以检错,但不可以纠错
以下是CRC码计算的样例:
海明校验码
在数据位之间特定位置插入k个校验位,k的值需要符合
如此一来,海明码有n+k位,假设校验位插入的位置分别为P(i),而它在海明码中的位置为H(j),则
如何校验呢:
将海明码下标转换为二进制,则可有n+k个长度为k的数,那么
$ P(i)=H(1)+H(2)+H(3)$ (这里是所有第i位为1的值进行异或操作)
校验海明码的步骤
- 在数据位间插入k个校验位,k的值符合$$2^k-1>=n+k$$(n为数据位的位数,k位校验位的位数),则n+k为海明码位数.
- 确定插入位置,即每一个校验位在海明码中的位置,假设每一位的位置为P(i)(每一位的值为P(i)),而他在海明码中的位置为H(j),则$$j=2^{i-1}$$
3、确定每一个校验位的值,将每一位H(j)化为的形式,即,然后对每一个
其中D(x)取决于P(i)中i的数值,但凡D(x)在H(j)中j能拆出i的都须加入异或操作队列中.
计算机安全
信息安全的基本要素
- 机密性
- 完整性
- 可用性
- 可控性
- 可审查性
计算机加密技术
对称加密算法
- 数据加密标准(Data Encryption Standard) 主要采用替换和移位的方法加密
- 三重DES 相当于将密钥的长度加倍.
- 国际数据加密算法(IDEA)
- 高级加密标准(AES) 基于排列和置换运算.排列是对数据重新进行安排,置换是将一个数据单元替换为另一个数据单元.
非对称加密算法
RSA算法
计算机认证技术
关键绩效指标
关键绩效指标(KPI,Key Performance Indicator)
- 认证机构:即数字证书的申请及签发机关
- 数字证书库:存储已签发的数字证书及公钥
- 密钥备份及恢复系统
- 证书作废系统
- 应用接口




